Study
-
https://www.youtube.com/playlist?list=PLtBw6njQRU-rwp5__7C0oIVt26ZgjG9NI
-
GPT-OSS-20B
- embedding 2880 dim
- RoPE
| abbr. | stand for | meaning |
|---|---|---|
| GQA | Grouped Query Attention | 分组查询注意力 |
| MHA | Multi-Head Attention | 多头注意力 |
| MLA | Multi-Head Latent Attention | 多头潜在注意力 |
| MoE | Mixture of Experts | 专家混合 |
| RoPE | Rotary Position Embedding | 旋转位置嵌入 |
| SL | Supervised Learning | 监督学习 |
| SSL | Self-Supervised Learning | 自监督学习 |
| WSL | Weakly Supervised Learning | 弱监督学习 |
| FFN | Feed Forward Network | 前馈神经网络 |
| en | cn |
|---|---|
| Bias | 偏差 |
| Overfitting | 过拟合 |
| Regularization | 正则化 |
| Underfitting | 欠拟合 |
| Variance | 方差 |
- https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
- https://magazine.sebastianraschka.com/p/from-gpt-2-to-gpt-oss-analyzing-the
- https://arxiv.org/
- https://yiyibooks.cn/
- 有一些 arxiv 的翻译
正则化
- 正则化 (Regularization)
- 目的: 防止模型过拟合
- 参数范数惩罚 (Parameter Norm Penalties)
- 通过在模型的损失函数(Loss Function)中添加一个与模型权重大小相关的“惩罚项”来实现。
- L2 正则化 (权重衰减, Weight Decay)
- L1 正则化 (Lasso)
- 弹性网络 (Elastic Net)
- L1 和 L2 正则化的混合体,同时包含了权重平方和与绝对值和的惩罚项。
- 架构设计与模型集成 (Architectural & Ensemble Methods)
- 通过改变模型的结构或训练方式来防止过拟合。
- Dropout (随机失活)
- 在训练过程中的每一步,都随机地“丢弃”(将其输出置为零)一部分神经元。
- 早停 (Early Stopping)
- 当模型在训练集上的性能仍在提升,但在验证集上的性能开始下降时,就立即停止训练。
- 模型集成 (Ensemble Methods)
- 训练多个独立的模型,然后将它们的预测结果进行平均或投票。
- 例如,随机森林(Random Forest)就是一种集成方法。
- 数据增强 (Data Augmentation)
- 核心思想是,既然数据不够多,那我们就人工地“创造”更多的数据。
- 对现有的训练数据进行各种随机的、轻微的变换,生成新的、合理的训练样本。
- 图像:
- 随机旋转、裁剪、缩放、翻转。
- 改变亮度、对比度、色调。
- 添加随机噪声。
- 文本
- 回译 (Back-translation): 将句子翻译成另一种语言,再翻译回来。
- 随机插入、删除或替换同义词。
- 噪声注入 (Noise Injection)
- 通过向网络的不同部分添加随机噪声来增强模型的鲁棒性。
- 权重噪声 (Weight Noise): 在训练的每一步,给模型的权重添加一些随机噪声。
- 激活值噪声 (Activation Noise): 对神经元的激活值添加噪声。
- 标签平滑 (Label Smoothing): 一种对标签添加噪声的方法。
- 它将原本“非黑即白”的硬标签(比如,分类为“猫”的概率是100%,是“狗”的概率是0%),变成更“柔和”的标签(比如,“猫”的概率是95%,是“狗”的概率是5%),防止模型对自己的预测“过于自信”。
| 类别 | 技术 | 核心思想 |
|---|---|---|
| 参数惩罚 | L1, L2, Elastic Net | 限制模型权重的大小,使其更“简单”。 |
| 架构/集成 | Dropout, Early Stopping | 随机改变网络结构或提前中断训练,避免过度学习。 |
| 数据增强 | 图像/文本增强 | 在不改变标签的前提下,创造更多样化的训练数据。 |
| 噪声注入 | 标签平滑等 | 向模型的权重、激活或标签中添加随机性,使其更鲁棒。 |
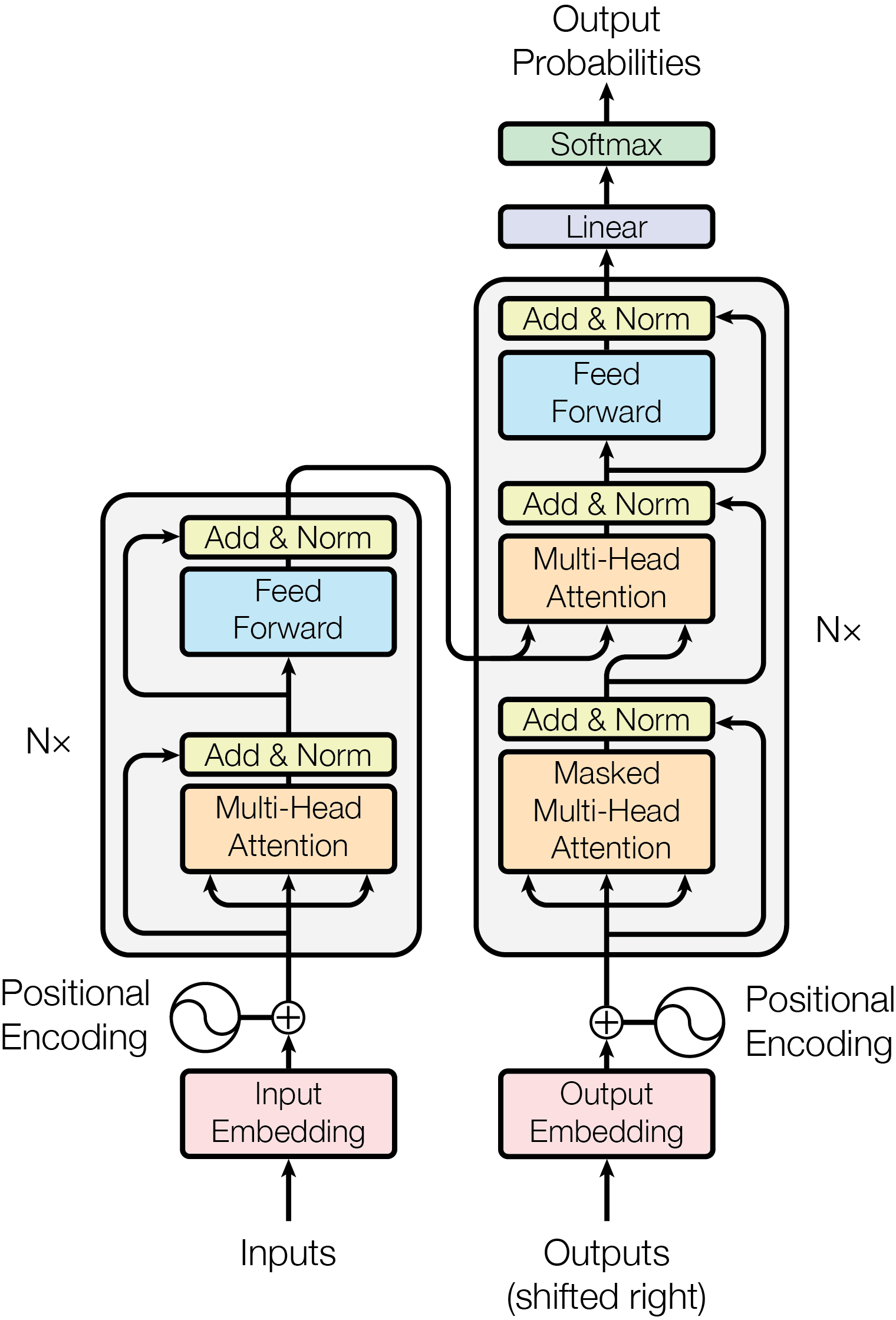
Transformer
- Tokenization - Embedding - Positional encoding - Transformer block - Attention
- Context QKV
- Attention Pattern
- Self Attention
- Cross Attention
- KV 不同 dataset
- Multi-head Attention
- Single Head Attention
- Sparse Attention Mechanism
- Blockwise Attention
- Linformer
- Reformer
- Ring Attention
- GQA - Grouped Query Attention
- SwiGUL
- 参考
- GPT3
- Q 12,288x128
- K 12,288x128
- 96 heads
- 12 layers
- 175B params
Attention Is All You Need
- 2017-06, Google
- 引入 Transformer 模型架构,改变了自然语言处理领域
- 打破了顺序处理的枷锁,实现了大规模并行计算。
- 极大地提升了模型捕捉“长距离依赖”的能力。
- RNN/LSTM 的时代与困境
- 计算效率低下 (无法并行) - 海量训练数据不现实
- 长距离依赖问题 (信息丢失)
- 用自注意力机制 (Self-Attention) 实现并行计算
- 用自注意力机制解决长距离依赖
- 深远实际意义
- 奠定了现代大语言模型 (LLM) 的基础
- 开启了“预训练+微调”的新范式
- 推动了模型规模的“军备竞赛”
- 跨领域的范式转移
- Attention Is All You Need
- https://yiyibooks.cn/arxiv/1706.03762v7/index.html
- Dive in
- https://nlp.seas.harvard.edu/annotated-transformer/
- https://jalammar.github.io/illustrated-transformer/
- Attention in transformers, step-by-step | Deep Learning Chapter 6 https://www.youtube.com/watch?v=eMlx5fFNoYc
- Decoder Only
- GPT-1, GPT-2, GPT-3
- 自回归语言模型 (Autoregressive LM) 逐字预测下一个词
- Encoder Only
- BERT, RoBERTa, ALBERT
- 掩码语言模型 (Masked LM) 掩码预测被遮盖的词
- Encoder-Decoder
- T5, BART
- 序列到序列 (Seq2Seq) 模型,适用于翻译等任务
- Next
- 生成 Q, K, V
- 对于输入序列中的每一个词嵌入向量,都通过乘以 , , 矩阵生成对应的 Q, K, V 向量。
- 计算注意力分数 (Score)
- 当前处理的词的 Q 向量与所有词的 K 向量进行点积,得到注意力分数。
- 归一化 (Normalization)
- 将分数转换成一个总和为 1 的概率分布
- 得到 注意力权重
- 加权求和 (Weighted Sum)